
A good PyTorch Learning material: https://pytorch.org/examples/
Traditional mothods:
- re-sampling
- re-weighting
New mothods based on:
- Diverse Experts Learning: Head\Medium\Tail classes with different experts.
- knowledge Distillation: share knowledge among different experts.
- Contrastive Learning: use different levels of data augmentations to reduce the label bias.
Long Tailed Dataset
- CIFAR100/10-LT imbalance factor(IF) is defined by $\beta = {N{max}}/{N{min}}$.
- ImageNet-LT and Places-LT: used Pareto distribution to sample the subsets.
- iNaturalist 2018: previously divided into many-shot, medium-shot, few-shot parts.
Summary
- self-supervised and self-distillation is the same concept that just apply two kinds of data augmentaion to the same image, and use either -plog(q) or KL(p||q) as the loss function. Another method is using decoder to reconstruct the imge, then use Mean Square Error to optimize the distance between the augmented image and the reconstructed image.
- different experts need different networks ??????
(ICCV2023) MDCS: More Diverse Experts with Consistency Self-distillation for Long-tailed Recognition
- It is good that more diverse experts and less variance among these experts. DL for the former, CS for the latter.
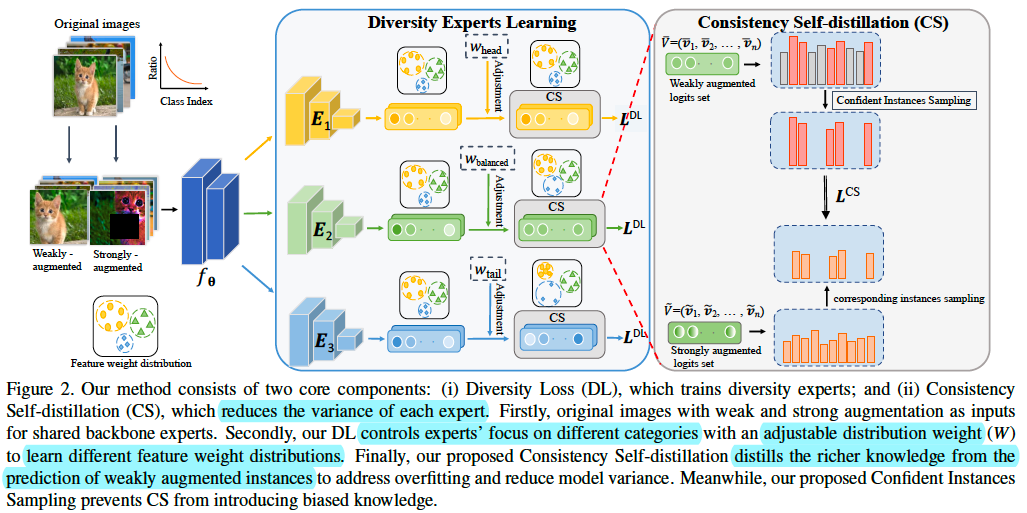
- DL (Diversity Loss) add different distribution weights w to CrossEntropyLoss for different experts. $ w = \lambda log(N^{C}) $. $N^{C}$ is a list consisting the number of training samples for each category.
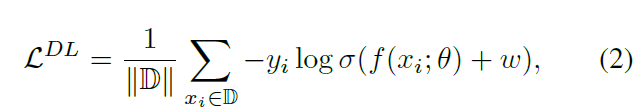
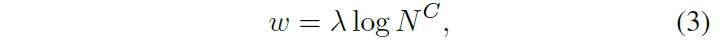
- CS (Consistency Self-distillation) means the weakly and strongly augmentation to an input image, their raw logits from the network output should be similar. The similarity between these versions is measured by KL-divergence. But before KL-divergence computation, the raw logits should be going through diversity softmax which has the weight distribution parameter $\lambda$ for logits adjustment.
- When $\lambda > 1$, it has the effect of generating a reversed weight of long-tailed distribution. ?????
- When $\lambda < 0$, it has the effect of aggravating the imbalance of original long-tailed distribution.
- When $\lambda$ in (0,1), it can weaken the influence of long-tailed distribution.
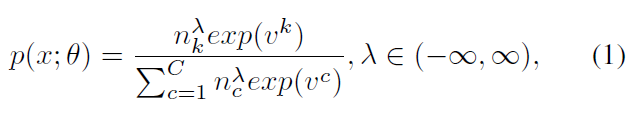
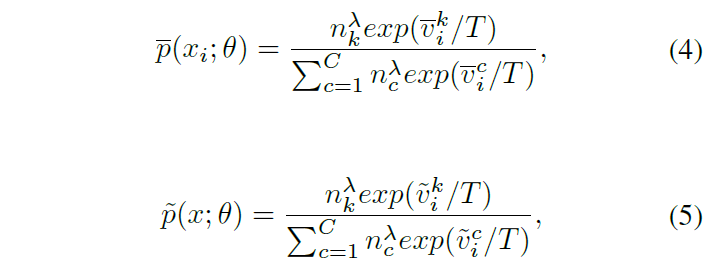
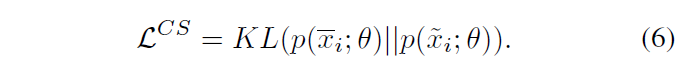
- CIS (Confident Instances Sampling) filters those correctly classified instances which can join the KL-divergence Loss to prevent CS distills from all instances introducing biased knowledge.
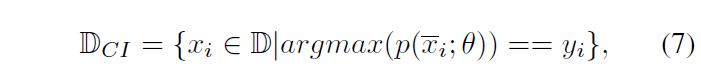
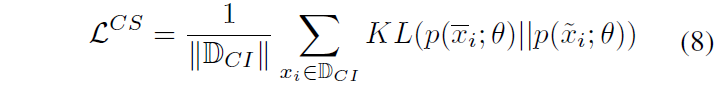
total loss

code: https://github.com/fistyee/MDCS
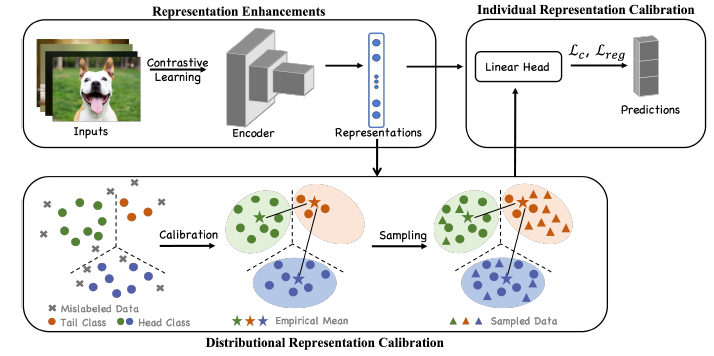
(ICCV2023) When Noisy Labels Meet Long Tail Dilemmas: A Representation Calibration Method
RCAL:
2 Problem: noisy labels and long tail class
MOCO code: https://github.com/facebookresearch/moco



(CVPR2023)Learning Imbalanced Data with Vision Transformers
code: https://github.com/XuZhengzhuo/LiVT
- Proposed Balanced version of Binary CrossEntroy Loss (Bal-BCE) instead of Balanced CrossEntropy (BCE).

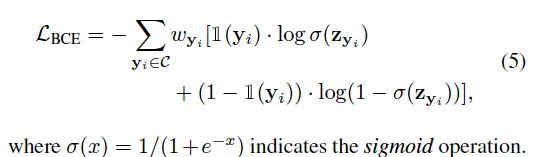
BCE logits bias is: $\log{\pi_{yi}}$
Bal-bCE logits bias is: $\log{\pi{yi}} – \log({1-\pi{y_i}})$
Bal-bCE
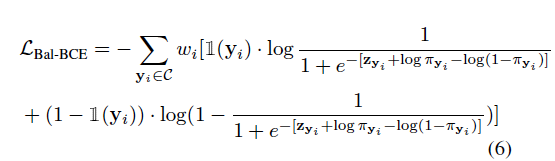
Bal-bCE can
- enlarges the margins to increase the difficulty of the tail(smaller $\pi_{y_i}$).
- further reduces the head (larger $\pi_{y_i}$) inter-class distances with larger positive values.
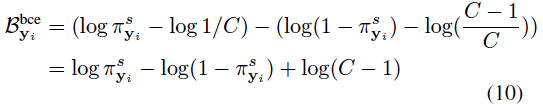
The extra term $log(C-1)$ will increase ViT’s training stability, expecially when the class number C gets larger.

(CVPR2022)Nested Collaborative Learning for Long-Tailed Visual Recognition
NCL
code: https://github.com/Bazinga699/NCL
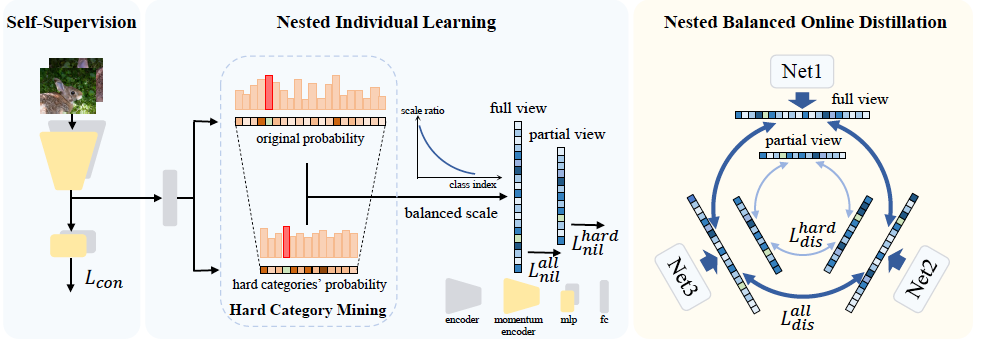
Hard Category Mining(HCM), how to select the hard categories.



Nested Individual Learning

Nested Balanced Online Distillation(NBOD)

Feature Enhancement via Self-Supervision
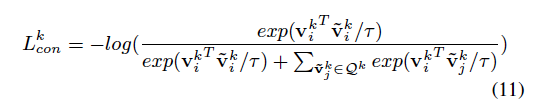
total loss
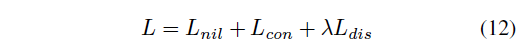
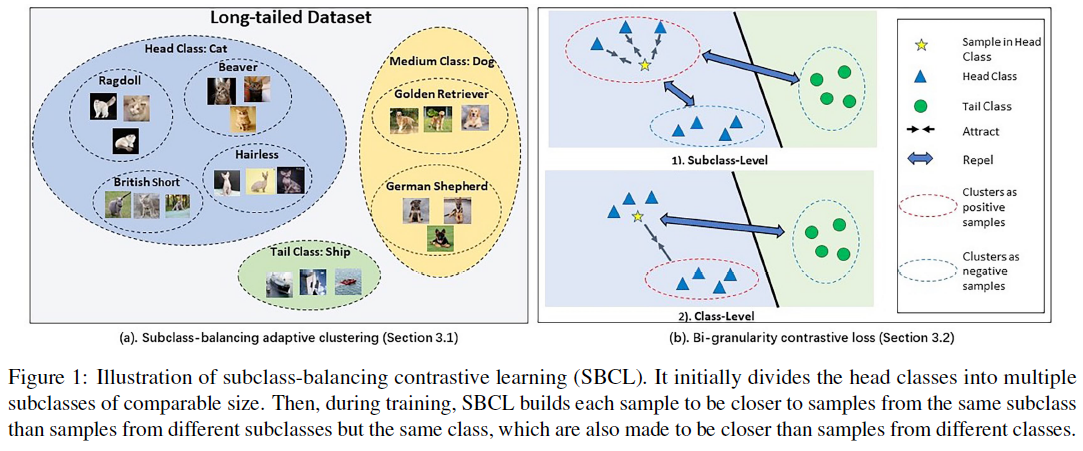
(ICCV2023**)Subclass-balancing Contrastive Learning for Long-tailed Recognition
SBCL
code: https://github.com/JackHck/SBCL
SCL(Supervised Contrastive Learning)

KCL(K-positive Contrastive Learning)
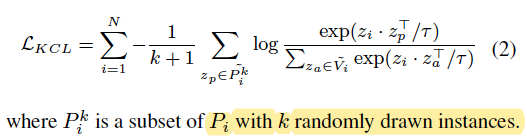
Architecture
cluster algorithm

SBCL (SubClass Balancing Contrastive Learning)

For supervised contrastive learning, a low temperature makes relative high penalty on feature distribution. So, $\tau_1<\tau_2$ means more penalty on the first term in the SBCL Loss, i.e. more tight in the same cluster.
Temperature update
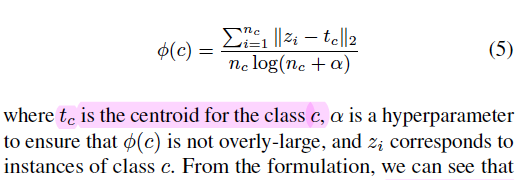

training algorithm

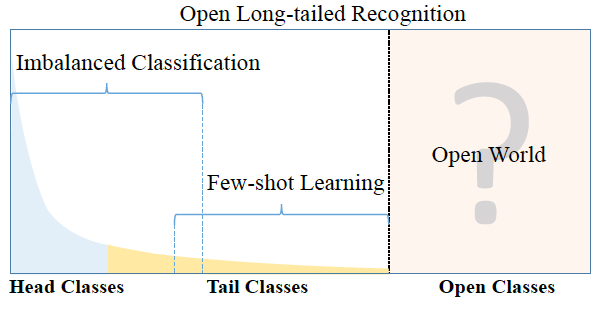
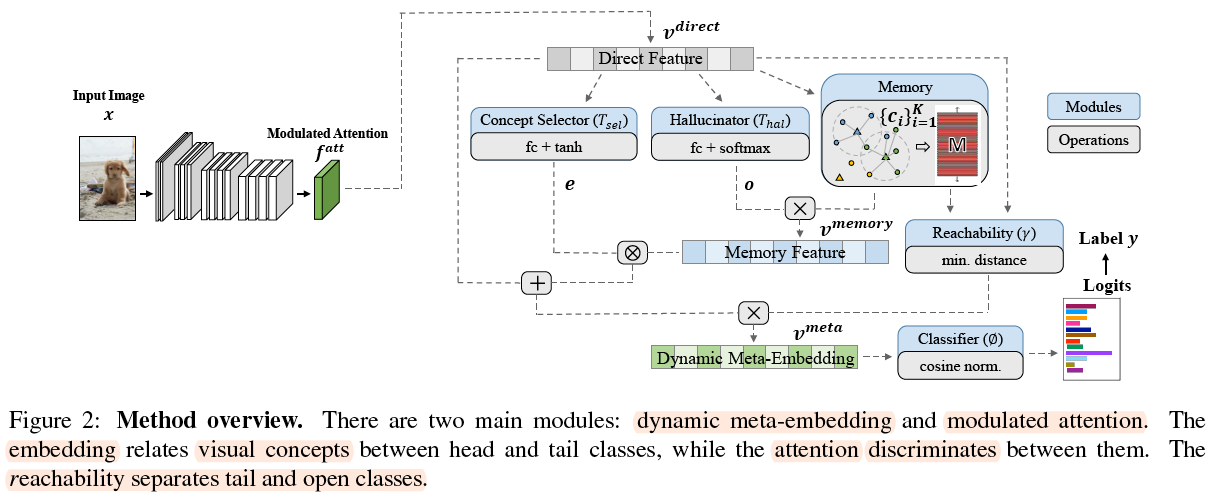
(CVPR2019**)Large-Scale Long-Tailed Recognition in an Open World
OLTR: Open Long Tailed Recognition
code: https://github.com/zhmiao/OpenLongTailRecognition-OLTR
The t-SNE and attention visulation shall be fouced on.
This work fills the void in practical benchmarks for imbalanced classification, few-shot learning, and open-set recognition.




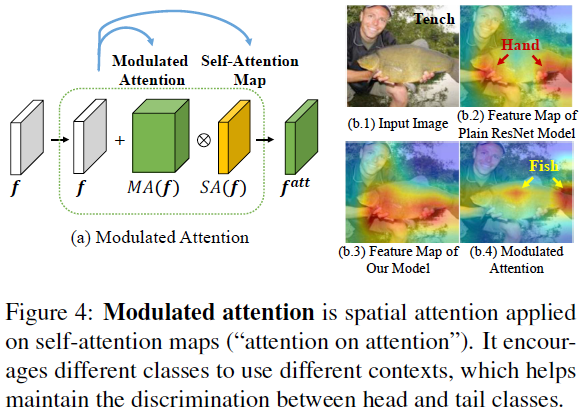

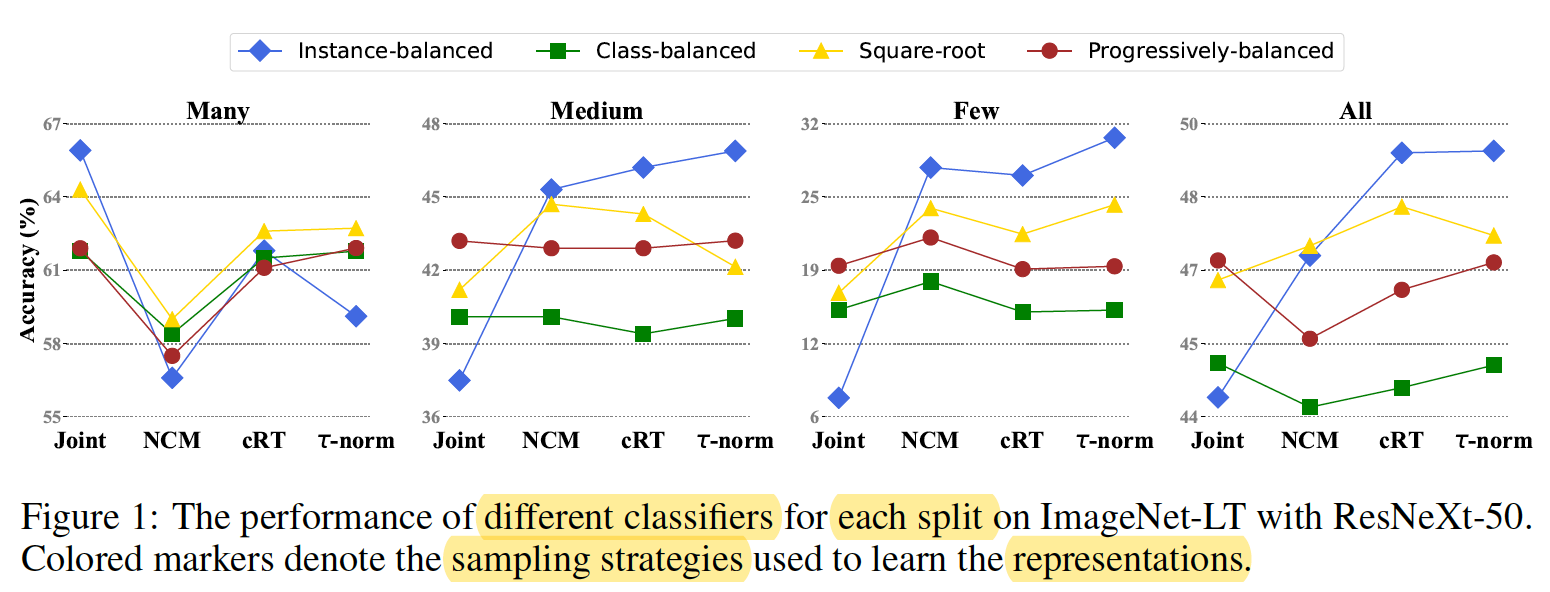
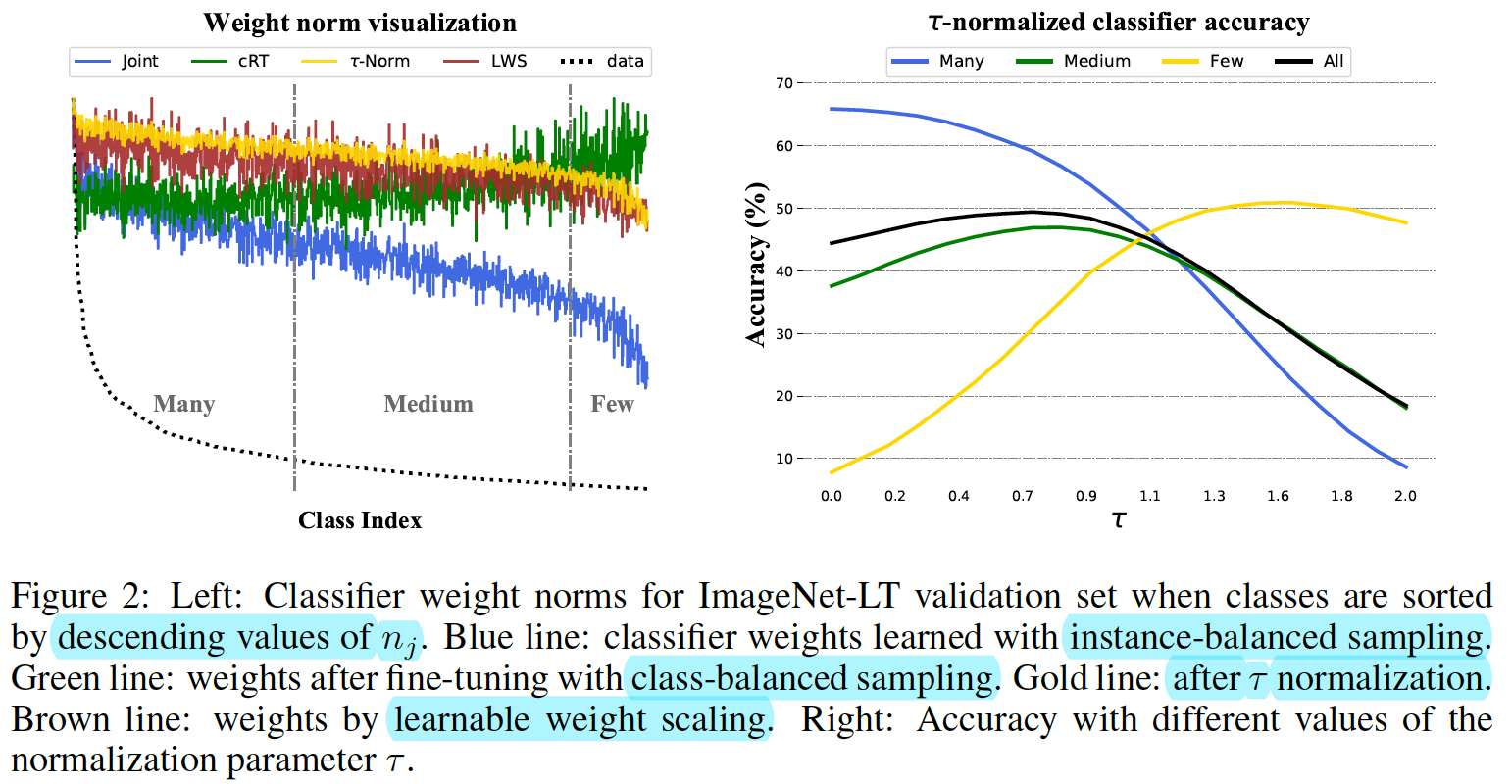
(ICLR2020)Decoupling Representation and Classifier for Long-Tailed Recognition
Following OLTR(2019)
code: https://github.com/facebookresearch/classifier-balancing
The findings are surprising:
- (1) data imbalance might not be an issue in learning high-quality representations;
- (2) with representations learned with the simplest instance-balanced (natural) sampling, it is also possible to achieve strong long-tailed recognition ability by adjusting only the classifier.





(ECCV2020)Learning From Multiple Experts: Self-paced Knowledge Distillation for Long-tailed Classification
Following OLTR(2019)
LFME: Learning From Multiple Experts, $1^{th}$ with multi-experts ???????
code: https://github.com/xiangly55/LFME
Heuristic: networks trained on less imbalanced subsets of the distribution often yield better performances than their jointly-trained counterparts.
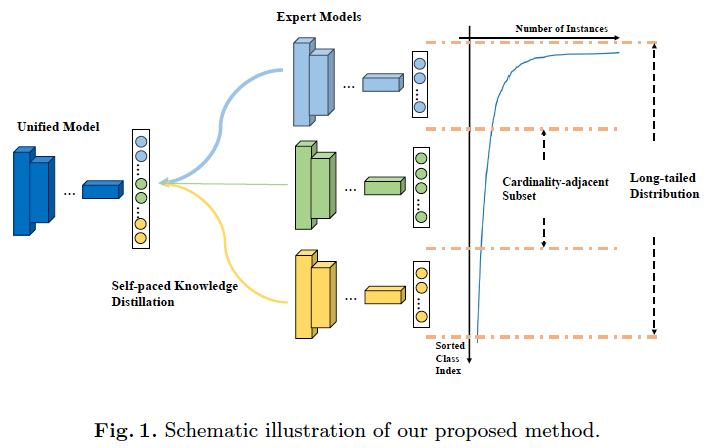
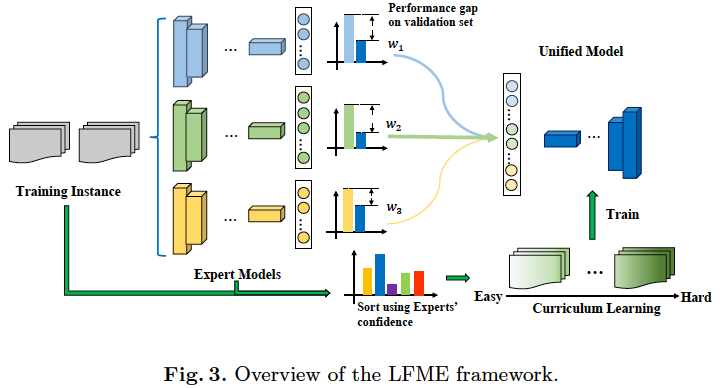
dataset partition and experts

Self-paced Expert Selection

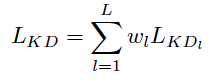
when $Acc_M$, i.e. the student model accuracy approaches to $Acc_E$, i.e. the experts model accuracy, the weight discrease from 1 to 0.
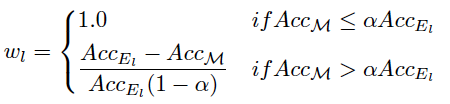
CrossEntropyLoss
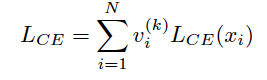

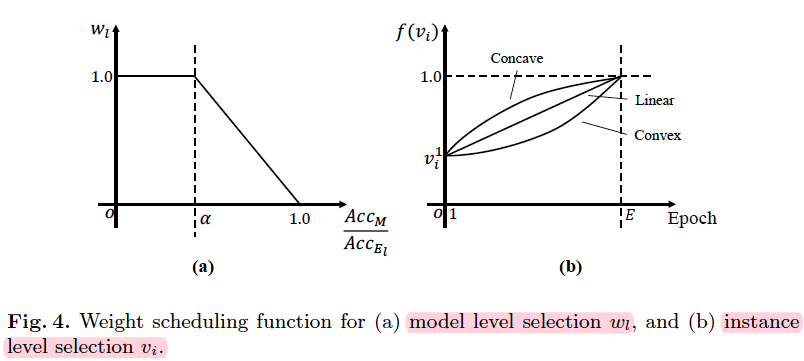
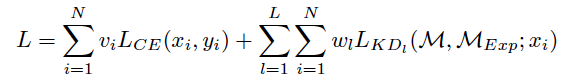
training process:

How to get the unified Model
I guess there is only one model template for all experts. The same model using different data constructs the conscept of different experts.
(ICCV2023**)Global Balanced Experts for Federated Long-Tailed Learning
code: https://github.com/Spinozaaa/Federated-Long-tailed-Learning
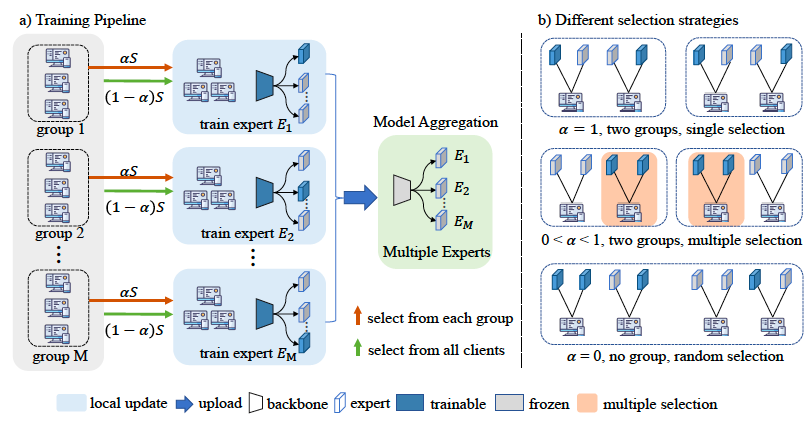
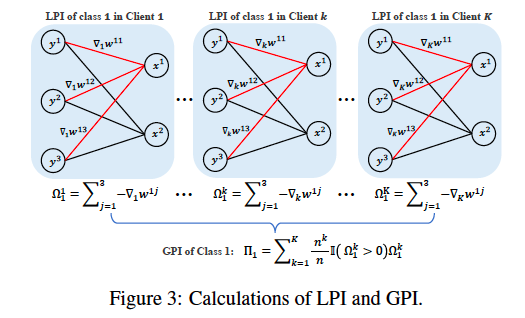


Above v is logits, s stands for softmax function. But how to get $\pi$ ???

However, the above content may not be enough for CVPR, so adding DP is a good choice. The hyperparameter fintuning process can be fed into the ablation study.


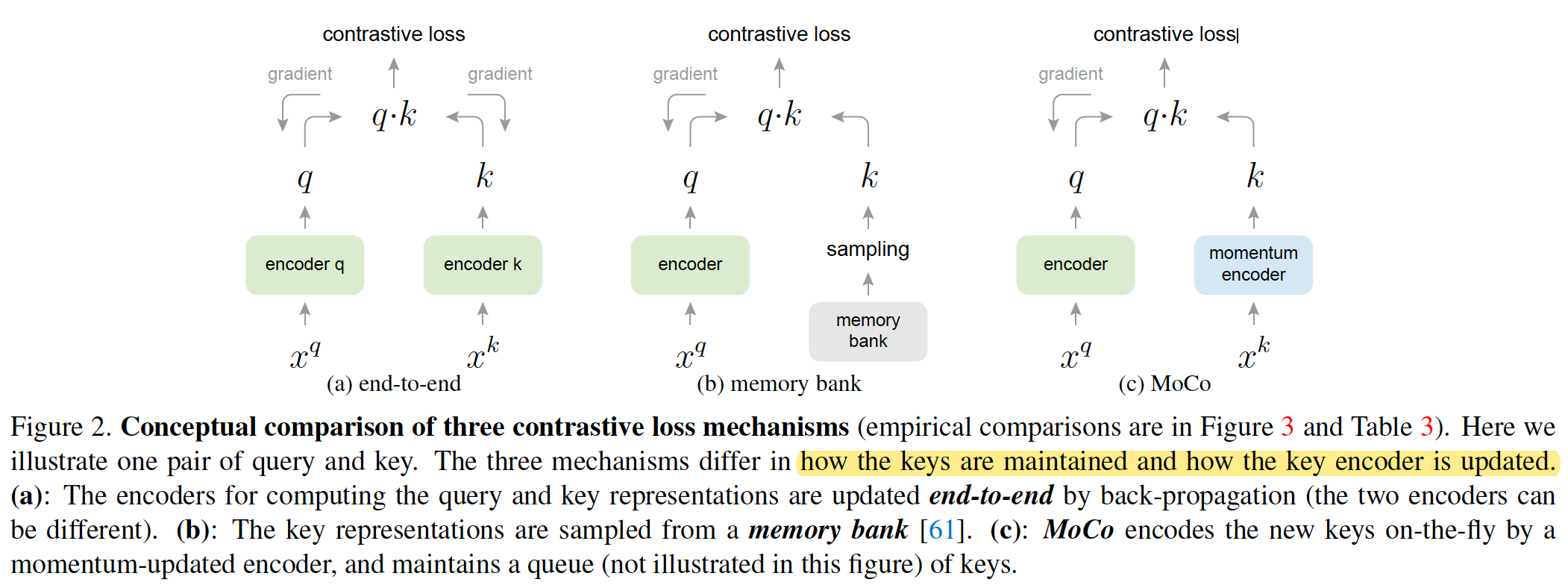
(CVPR2020)Momentum Contrast for Unsupervised Visual Representation Learning
MOCO
code: https://github.com/facebookresearch/moco




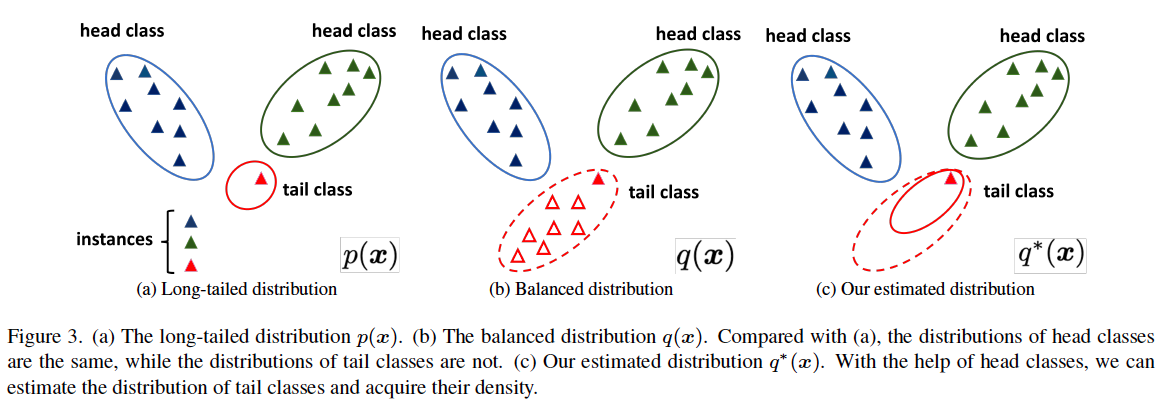
(CVPR2023) Transfer Knowledge from Head to Tail:Uncertainty Calibration under Long-tailed Distribution
code:https://github.com/JiahaoChen1
wasserstein distance







XYZWHL
(CVPR2023) Curvature-Balanced Feature Manifold Learning for Long-Tailed Classification
no code.
It opens up a geometric analysis perspective on model bias and reminds researchers to pay attention to model bias on non-long-tailed and even sample balanced datasets.
(ICCV2023) Learning in Imperfect Environment: Multi-Label Classification with Long-Tailed Distribution and Partial Labels
It presented a fire-new task called PLT-MLC and correspondingly developed a novel framework, named COMIC. COMIC simultaneously addresses the partial labeling and long-tailed environments in a Correction → Modification → Balance learning manner.
code: https://github.com/wannature/COMIC
(CVPR2023)Towards Realistic Long-Tailed Semi-Supervised Learning: Consistency Is All You Need
unlabeled dataset: STL10-LT
ACR realizes the dynamic refinery of pseudolabels
for various distributions in a unified formula by estimating
the true class distribution of unlabeled data.
(ICLR2021)LONG-TAIL LEARNING VIA LOGIT ADJUSTMENT
code: https://github.com/google-research/google-research/tree/master/logit_adjustment
tensorflow
(ECCV2020)Distribution-Balanced Loss for Multi-Label Classification in Long-Tailed Datasets
code: https://github.com/wutong16/DistributionBalancedLoss
It presented a new loss function called Distribution-Balanced Loss for the multi-label recognition problems that exhibit long-tailed class distributions
(CVPR2023) Balanced Product of Calibrated Experts for Long-Tailed Recognition
BalPoE
code: https://github.com/emasa/BalPoE-CalibratedLT
Calibrated
(ICCV2023) Local and Global Logit Adjustments for Long-Tailed Learning
no code
(CVPR2023) FEND: A Future Enhanced Distribution-Aware Contrastive Learning Framework for Long-tail Trajectory Prediction
code: https://github.com/ynw2021/FEND JUST A README.md
(CVPR2023) Use Your Head: Improving Long-Tail Video Recognition
code: https://github.com/tobyperrett/lmr
(CVPR2023) Class-Conditional Sharpness-Aware Minimization for Deep Long-Tailed Recognition
code: https://github.com/zzpustc/CC-SAM
(CVPR2023) Long-Tailed Visual Recognition via Self-Heterogeneous Integration with Knowledge Excavation
code: https://github.com/jinyan-06/SHIKE
(CVPR2023) Rethinking Image Super Resolution from Long-Tailed Distribution Learning Perspective
no code
(CVPR2023) SuperDisco: Super-Class Discovery Improves Visual Recognition for the Long-Tail
no code
(CVPR2023) No One Left Behind: Improving the Worst Categories in Long-Tailed Learning
no code
(CVPR2023) Global and Local Mixture Consistency Cumulative Learning for Long-tailed Visual Recognitions
code: https://github.com/ynu-yangpeng/GLMC
(CVPR2022) Trustworthy Long-Tailed Classification
code: https://github.com/lblaoke/TLC
(CVPR2021) Improving Calibration for Long-Tailed Recognition
code: https://github.com/dvlab-research/MiSLAS
(CVPR2020) Equalization Loss for Long-Tailed Object Recognition
code: https://github.com/tztztztztz/eql.detectron2
(CVPR2019) Class-Balanced Loss Based on Effective Number of Samples
code : https://github.com/richardaecn/class-balanced-loss
(ICCV2023) AREA: Adaptive Reweighting via Effective Area for Long-Tailed Classification
code: https://github.com/xiaohua-chen/AREA
(ICCV2023) Boosting Long-tailed Object Detection via Step-wise Learning on Smooth-tail Data
no code
(ICCV2023) Reconciling Object-Level and Global-Level Objectives for Long-Tail Detection
code: https://github.com/EricZsy/ROG
(ICCV2023) Label-Noise Learning with Intrinsically Long-Tailed Data
code: https://github.com/Wakings/TABASCO
(NIPS2019) Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss
code: https://github.com/kaidic/LDAM-DRW
(NIPS2020) Long-Tailed Classification by Keeping the Good and Removing the Bad Momentum Causal Effect
code: https://github.com/KaihuaTang/Long-Tailed-Recognition.pytorch
(NIPS2020) Rethinking the Value of Labels for Improving Class-Imbalanced Learning
code: https://github.com/YyzHarry/imbalanced-semi-self
打赏作者
