
第 14 章 SAC 算法
14.1 简介
之前的章节提到过在线策略算法的采样效率比较低,我们通常更倾向于使用离线策略算法。然而,虽然 DDPG 是离线策略算法,但是它的训练非常不稳定,收敛性较差,对超参数比较敏感,也难以适应不同的复杂环境。2018 年,一个更加稳定的离线策略算法 Soft Actor-Critic(SAC)被提出。SAC 的前身是 Soft Q-learning,它们都属于最大熵强化学习的范畴。Soft Q-learning 不存在一个显式的策略函数,而是使用一个函数Q的波尔兹曼分布,在连续空间下求解非常麻烦。于是 SAC 提出使用一个 Actor 表示策略函数,从而解决这个问题。目前,在无模型的强化学习算法中,SAC 是一个非常高效的算法,它学习一个随机性策略,在不少标准环境中取得了领先的成绩。
14.2 最大熵强化学习
熵(entropy)表示对一个随机变量的随机程度的度量。具体而言,如果 \(X\) 是一个随机变量,且它的概率密度函数为 \(p\) ,那么它的熵 \(H\) 就被定义为
在强化学习中,我们可以使用 \(H(\pi(\cdot|s))\) 来表示策略 \(\pi\) 在状态 \(s\) 下的随机程度。
最大熵强化学习(maximum entropy RL)的思想就是除了要最大化累积奖励,还要使得策略更加随机。如此,强化学习的目标中就加入了一项熵的正则项,定义为
\pi^*=\arg \max _\pi \mathbb{E}_\pi\left[\sum_t r\left(s_t, a_t\right)+\alpha H\left(\pi\left(\cdot \mid s_t\right)\right)\right]
\)
其中,\(\alpha\) 是一个正则化的系数,用来控制熵的重要程度。
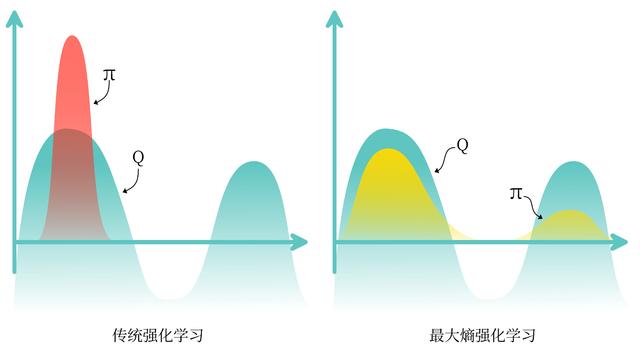
熵正则化增加了强化学习算法的探索程度,\(\alpha\) 越大,探索性就越强,有助于加速后续的策略学习,并减少策略陷入较差的局部最优的可能性。传统强化学习和最大熵强化学习的区别如图 14-1 所示。
14.3 Soft 策略迭代
在最大熵强化学习框架中,由于目标函数发生了变化,其他的一些定义也有相应的变化。首先,我们看一下 Soft 贝尔曼方程:
Q\left(s_t, a_t\right)=r\left(s_t, a_t\right)+\gamma \mathbb{E}_{s_{t+1}}\left[V\left(s_{t+1}\right)\right]
\)
其中,状态价值函数被写为
V\left(s_t\right)=\mathbb{E}_{a_1 \sim \pi}\left[Q\left(s_t, a_t\right)-\alpha \log \pi\left(a_t \mid s_t\right)\right]=\mathbb{E}_{a_t \sim \pi}\left[Q\left(s_t, a_t\right)\right]+H\left(\pi\left(\cdot \mid s_t\right)\right)
\)
于是,根据该 Soft 贝尔曼方程,在有限的状态和动作空间情况下,Soft 策略评估可以收敛到策略 \(\pi\) 的 Soft \(Q\) 函数。然后,根据如下 Soft 策略提升公式可以改进策略:
\pi_{\mathrm{new}}=\arg \min _{\pi^{\prime}} D_{K L}\left(\pi^{\prime}(\cdot \mid s), \frac{\exp \left(\frac{1}{\alpha} Q^{\pi_{\mathrm{old}}}(s, \cdot)\right)}{Z^{\pi_{\text {old }}(s, \cdot)}}\right)
\)
重复交替使用 Soft 策略评估和 Soft 策略提升,最终策略可以收敛到最大熵强化学习目标中的最优策略。但该 Soft 策略迭代方法只适用于表格型(tabular)设置的情况,即状态空间和动作空间是有限的情况。在连续空间下,我们需要通过参数化函数Q和策略 \(\pi\) 来近似这样的迭代。
14.4 SAC
在 SAC 算法中,我们为两个动作价值函数 Q(参数分别为 \(\omega_1\) 和 \(\omega_2\))和一个策略函数 \(\pi\) (参数为 \(\theta\) )建模。基于 Double DQN 的思想,SAC 使用两个Q网络,但每次用Q网络时会挑选一个Q值小的网络,从而缓解Q值过高估计的问题。任意一个函数Q的损失函数为:
L_Q(\omega)=\mathbb{E}_{\left(s_t, a_t, r_t, s_{t+1}\right) \sim R}\left[\frac{1}{2}\left(Q_\omega\left(s_t, a_t\right)-\left(r_t+\gamma V_{\omega^{-}}\left(s_{t+1}\right)\right)\right)^2\right]
\)
其中,R是策略过去收集的数据,因为 SAC 是一种离线策略算法。为了让训练更加稳定,这里使用了目标Q网络 \(Q_{\omega^{-}}\),同样是两个目标Q网络,与两个Q网络一一对应。SAC 中目标Q网络的更新方式与 DDPG 中的更新方式一样。
策略 \(\pi\) 的损失函数由 KL 散度得到,化简后为:
L_\pi(\theta)=\mathbb{E}_{s_t \sim R, a_t \sim \pi_\theta}\left[\alpha \log \left(\pi_\theta\left(a_t \mid s_t\right)\right)-Q_\omega\left(s_t, a_t\right)\right]
\)
可以理解为最大化函数 \(V\),因为有。
V\left(s_t\right)=\mathbb{E}_{a_t \sim \pi}\left[Q\left(s_t, a_t\right)-\alpha \log \pi\left(a_t \mid s_t\right)\right] \text { 。 }
\)
对连续动作空间的环境,SAC 算法的策略输出高斯分布的均值和标准差,但是根据高斯分布来采样动作的过程是不可导的。因此,我们需要用到重参数化技巧(reparameterization trick)。重参数化的做法是先从一个单位高斯分布 \(\mathcal{N}\) 采样,再把采样值乘以标准差后加上均值。这样就可以认为是从策略高斯分布采样,并且这样对于策略函数是可导的。我们将其表示为 \(a_t = f_{\theta}(\epsilon_{t};s_t)\) ,其中 \(\epsilon\) 是一个噪声随机变量。同时考虑到两个函数Q,重写策略的损失函数:
L_\pi(\theta)=\mathbb{E}_{s_t \sim R_i \epsilon_t \sim \mathcal{N}}\left[\alpha \log \left(\pi_\theta\left(f_\theta\left(\epsilon_t ; s_t\right) \mid s_t\right)\right)-\min _{j=1,2} Q_{\omega_j}\left(s_t, f_\theta\left(\epsilon_t ; s_t\right)\right)\right]
\)
自动调整熵正则项
在 SAC 算法中,如何选择熵正则项的系数非常重要。在不同的状态下需要不同大小的熵:在最优动作不确定的某个状态下,熵的取值应该大一点;而在某个最优动作比较确定的状态下,熵的取值可以小一点。为了自动调整熵正则项,SAC 将强化学习的目标改写为一个带约束的优化问题:
\max _\pi \mathbb{E}_\pi\left[\sum_t r\left(s_t, a_t\right)\right] \text { s.t. } \quad \mathbb{E}_{\left(s_t, a_t\right) \sim \rho_\pi}\left[-\log \left(\pi_t\left(a_t \mid s_t\right)\right)\right] \geq \mathcal{H}_0
\)
也就是最大化期望回报,同时约束熵的均值大于 \(\mathcal{H}_0\)。通过一些数学技巧化简后,得到 \(\alpha\) 的损失函数:
L(\alpha)=\mathbb{E}_{s_t \sim R, a_t \sim \pi\left(\cdot \mid s_t\right)}\left[-\alpha \log \pi\left(a_t \mid s_t\right)-\alpha \mathcal{H}_0\right]
\)
即当策略的熵低于目标值 \(\mathcal{H}_0\) 时,训练目标 \(L(\alpha)\) 会使 \(\alpha\) 的值增大,进而在上述最小化损失函数 \(L_{\pi}(\theta)\) 的过程中增加了策略熵对应项的重要性;而当策略的熵高于目标值 \(\mathcal{H}_0\) 时,训练目标 \(L(\alpha)\) 会使 \(\alpha\) 的值减小,进而使得策略训练时更专注于价值提升。
至此,我们介绍完了 SAC 算法的整体思想,它的具体算法流程如下:
- 用随机的网络参数 \(\omega_1\) , 和 \(\omega_2\) 分别初始化 Critic 网络 \(Q_{\omega_1}(s,a)\), \(Q_{\omega_2}(s,a)\) 和 Actor 网络 \(\pi_{\theta}(s)\)
- 复制相同的参数 \(\omega^{-}_1 \leftarrow \omega_1\) ,\(\omega^{-}_2 \leftarrow \omega_2\) ,分别初始化目标网络 \(Q_{\omega^{-}_1}\) 和 \(Q_{\omega^{-}_2}\)
- 初始化经验回放池R
- for 序列 \(e = 1 \rightarrow E\) do
- 获取环境初始状态 \(s_1\)
- for 时间步 \(t = 1 \rightarrow T\) do
- 根据当前策略选择动作 \(a_t = \pi_{\pi}(s_t)\)
- 执行动作 \(a_t\) ,获得奖励 \(r_t\) ,环境状态变为 \(s_{t+1}\)
- 将 \(\left(s_t, a_t, r_t, s_{t+1}\right)\) 存入回放池 \(R\)
- for 训练轮数 \(k=1 \rightarrow K\) do
- 从 \(R\) 中采样 \(N\) 个元组 \(\left\{\left(s_i, a_i, r_i, s_{i+1}\right)\right\}_{i=1, \ldots, N}\)
- 对每个元组,用目标网络计算 \(y_i=r_i+\gamma \min _{j=1,2} Q_{\omega_j^{-}}\left(s_{i+1}, a_{i+1}\right)-\alpha \log \pi_\theta\left(a_{i+1} \mid s_{i+1}\right)\) ,其中 \(a_{i+1} \sim \pi_\theta\left(\cdot \mid s_{i+1}\right)\)
- 对两个 Critic 网络都进行如下更新:对 \(j=1,2\) ,最小化损失函数 \(L=\frac{1}{N} \sum_{i=1}^N\left(y_i-Q_{\omega_j}\left(s_i, a_i\right)\right)^2\)
- 用重参数化技巧采样动作 \(\tilde{a}_i\) ,然后用以下损失函数更新当前 Actor 网络:\(L_\pi(\theta)=\frac{1}{N} \sum_{i=1}^N\left(\alpha \log \pi_\theta\left(\tilde{a}_i \mid s_i\right)-\min _{j=1,2} Q_{\omega_j}\left(s_i, \tilde{a}_i\right)\right)\)
- 更新熵正则项的系数 \(\alpha\)
- 更新目标网络:\(\omega^{-}_1 \rightarrow \tau \omega_1 + (1-\tau) \omega^{-}_1 \omega^{-}_2 \rightarrow \tau \omega_2 + (1-\tau) \omega^{-}_2\)
- end for
- end for
- end for
14.5 SAC 代码实践
我们来看一下 SAC 的代码实现,首先在倒立摆环境下进行实验,然后再尝试将 SAC 应用到与离散动作交互的车杆环境。
首先我们导入需要用到的库。
import random
import gym
import numpy as np
from tqdm import tqdm
import torch
import torch.nn.functional as F
from torch.distributions import Normal
import matplotlib.pyplot as plt
import rl_utils接下来定义策略网络和价值网络。由于处理的是与连续动作交互的环境,策略网络输出一个高斯分布的均值和标准差来表示动作分布;而价值网络的输入是状态和动作的拼接向量,输出一个实数来表示动作价值。
class PolicyNetContinuous(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim, action_bound):
super(PolicyNetContinuous, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc_mu = torch.nn.Linear(hidden_dim, action_dim)
self.fc_std = torch.nn.Linear(hidden_dim, action_dim)
self.action_bound = action_bound
def forward(self, x):
x = F.relu(self.fc1(x))
mu = self.fc_mu(x)
std = F.softplus(self.fc_std(x))
dist = Normal(mu, std)
normal_sample = dist.rsample() # rsample()是重参数化采样
log_prob = dist.log_prob(normal_sample)
action = torch.tanh(normal_sample)
# 计算tanh_normal分布的对数概率密度
log_prob = log_prob - torch.log(1 - torch.tanh(action).pow(2) + 1e-7)
action = action * self.action_bound
return action, log_prob
class QValueNetContinuous(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(QValueNetContinuous, self).__init__()
self.fc1 = torch.nn.Linear(state_dim + action_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)
self.fc_out = torch.nn.Linear(hidden_dim, 1)
def forward(self, x, a):
cat = torch.cat([x, a], dim=1)
x = F.relu(self.fc1(cat))
x = F.relu(self.fc2(x))
return self.fc_out(x)然后我们来看一下 SAC 算法的主要代码。如 14.4 节所述,SAC 使用两个 Critic 网络 \(Q_{\omega_1}\) 和 \(Q_{\omega_2}\) 来使 Actor 的训练更稳定,而这两个 Critic 网络在训练时则各自需要一个目标价值网络。因此,SAC 算法一共用到 5 个网络,分别是一个策略网络、两个价值网络和两个目标价值网络。
class SACContinuous:
''' 处理连续动作的SAC算法 '''
def __init__(self, state_dim, hidden_dim, action_dim, action_bound,
actor_lr, critic_lr, alpha_lr, target_entropy, tau, gamma,
device):
self.actor = PolicyNetContinuous(state_dim, hidden_dim, action_dim,
action_bound).to(device) # 策略网络
self.critic_1 = QValueNetContinuous(state_dim, hidden_dim,
action_dim).to(device) # 第一个Q网络
self.critic_2 = QValueNetContinuous(state_dim, hidden_dim,
action_dim).to(device) # 第二个Q网络
self.target_critic_1 = QValueNetContinuous(state_dim,
hidden_dim, action_dim).to(
device) # 第一个目标Q网络
self.target_critic_2 = QValueNetContinuous(state_dim,
hidden_dim, action_dim).to(
device) # 第二个目标Q网络
# 令目标Q网络的初始参数和Q网络一样
self.target_critic_1.load_state_dict(self.critic_1.state_dict())
self.target_critic_2.load_state_dict(self.critic_2.state_dict())
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),
lr=actor_lr)
self.critic_1_optimizer = torch.optim.Adam(self.critic_1.parameters(),
lr=critic_lr)
self.critic_2_optimizer = torch.optim.Adam(self.critic_2.parameters(),
lr=critic_lr)
# 使用alpha的log值,可以使训练结果比较稳定
self.log_alpha = torch.tensor(np.log(0.01), dtype=torch.float)
self.log_alpha.requires_grad = True # 可以对alpha求梯度
self.log_alpha_optimizer = torch.optim.Adam([self.log_alpha],
lr=alpha_lr)
self.target_entropy = target_entropy # 目标熵的大小
self.gamma = gamma
self.tau = tau
self.device = device
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.actor(state)[0]
return [action.item()]
def calc_target(self, rewards, next_states, dones): # 计算目标Q值
next_actions, log_prob = self.actor(next_states)
entropy = -log_prob
q1_value = self.target_critic_1(next_states, next_actions)
q2_value = self.target_critic_2(next_states, next_actions)
next_value = torch.min(q1_value,
q2_value) + self.log_alpha.exp() * entropy
td_target = rewards + self.gamma * next_value * (1 - dones)
return td_target
def soft_update(self, net, target_net):
for param_target, param in zip(target_net.parameters(),
net.parameters()):
param_target.data.copy_(param_target.data * (1.0 - self.tau) +
param.data * self.tau)
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions'],
dtype=torch.float).view(-1, 1).to(self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
# 和之前章节一样,对倒立摆环境的奖励进行重塑以便训练
rewards = (rewards + 8.0) / 8.0
# 更新两个Q网络
td_target = self.calc_target(rewards, next_states, dones)
critic_1_loss = torch.mean(
F.mse_loss(self.critic_1(states, actions), td_target.detach()))
critic_2_loss = torch.mean(
F.mse_loss(self.critic_2(states, actions), td_target.detach()))
self.critic_1_optimizer.zero_grad()
critic_1_loss.backward()
self.critic_1_optimizer.step()
self.critic_2_optimizer.zero_grad()
critic_2_loss.backward()
self.critic_2_optimizer.step()
# 更新策略网络
new_actions, log_prob = self.actor(states)
entropy = -log_prob
q1_value = self.critic_1(states, new_actions)
q2_value = self.critic_2(states, new_actions)
actor_loss = torch.mean(-self.log_alpha.exp() * entropy -
torch.min(q1_value, q2_value))
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# 更新alpha值
alpha_loss = torch.mean(
(entropy - self.target_entropy).detach() * self.log_alpha.exp())
self.log_alpha_optimizer.zero_grad()
alpha_loss.backward()
self.log_alpha_optimizer.step()
self.soft_update(self.critic_1, self.target_critic_1)
self.soft_update(self.critic_2, self.target_critic_2)# 接下来我们就在倒立摆环境上尝试一下 SAC 算法吧!
env_name = 'Pendulum-v1'
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
action_bound = env.action_space.high[0] # 动作最大值
random.seed(0)
np.random.seed(0)
env.seed(0)
torch.manual_seed(0)
actor_lr = 3e-4
critic_lr = 3e-3
alpha_lr = 3e-4
num_episodes = 100
hidden_dim = 128
gamma = 0.99
tau = 0.005 # 软更新参数
buffer_size = 100000
minimal_size = 1000
batch_size = 64
target_entropy = -env.action_space.shape[0]
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
replay_buffer = rl_utils.ReplayBuffer(buffer_size)
agent = SACContinuous(state_dim, hidden_dim, action_dim, action_bound,
actor_lr, critic_lr, alpha_lr, target_entropy, tau,
gamma, device)
return_list = rl_utils.train_off_policy_agent(env, agent, num_episodes,
replay_buffer, minimal_size,
batch_size) /home/aikedaer/.local/lib/python3.9/site-packages/gym/core.py:317: DeprecationWarning: [33mWARN: Initializing wrapper in old step API which returns one bool instead of two. It is recommended to set `new_step_api=True` to use new step API. This will be the default behaviour in future.[0m
deprecation(
/home/aikedaer/.local/lib/python3.9/site-packages/gym/wrappers/step_api_compatibility.py:39: DeprecationWarning: [33mWARN: Initializing environment in old step API which returns one bool instead of two. It is recommended to set `new_step_api=True` to use new step API. This will be the default behaviour in future.[0m
deprecation(
/home/aikedaer/.local/lib/python3.9/site-packages/gym/core.py:256: DeprecationWarning: [33mWARN: Function `env.seed(seed)` is marked as deprecated and will be removed in the future. Please use `env.reset(seed=seed)` instead.[0m
deprecation(
Iteration 0: 0%| | 0/10 [00:00<?, ?it/s]/tmp/ipykernel_10470/2202922912.py:38: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:233.)
state = torch.tensor([state], dtype=torch.float).to(self.device)
Iteration 0: 100%|██████████| 10/10 [01:00<00:00, 6.07s/it, episode=10, return=-1499.921]
Iteration 1: 100%|██████████| 10/10 [01:57<00:00, 11.77s/it, episode=20, return=-1241.360]
Iteration 2: 100%|██████████| 10/10 [02:03<00:00, 12.34s/it, episode=30, return=-241.750]
Iteration 3: 100%|██████████| 10/10 [02:07<00:00, 12.78s/it, episode=40, return=-169.344]
Iteration 4: 100%|██████████| 10/10 [02:09<00:00, 12.90s/it, episode=50, return=-197.100]
Iteration 5: 100%|██████████| 10/10 [02:02<00:00, 12.28s/it, episode=60, return=-137.687]
Iteration 6: 100%|██████████| 10/10 [01:55<00:00, 11.58s/it, episode=70, return=-173.344]
Iteration 7: 100%|██████████| 10/10 [01:59<00:00, 11.94s/it, episode=80, return=-191.548]
Iteration 8: 100%|██████████| 10/10 [01:55<00:00, 11.59s/it, episode=90, return=-162.635]
Iteration 9: 100%|██████████| 10/10 [01:54<00:00, 11.43s/it, episode=100, return=-213.531]
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('SAC on {}'.format(env_name))
plt.show()
mv_return = rl_utils.moving_average(return_list, 9)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('SAC on {}'.format(env_name))
plt.show()


可以发现,SAC 在倒立摆环境中的表现非常出色。SAC 算法原本是针对连续动作交互的环境提出的,那一个比较自然的问题便是:SAC 能否处理与离散动作交互的环境呢?答案是肯定的,但是我们要做一些相应的修改。首先,策略网络和价值网络的网络结构将发生如下改变:
- 策略网络的输出修改为在离散动作空间上的 softmax 分布;
- 价值网络直接接收状态和离散动作空间的分布作为输入。
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1)
class QValueNet(torch.nn.Module):
''' 只有一层隐藏层的Q网络 '''
def __init__(self, state_dim, hidden_dim, action_dim):
super(QValueNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)该策略网络输出一个离散的动作分布,所以在价值网络的学习过程中,不需要再对下一个动作 \(a_{t+1}\) 进行采样,而是直接通过概率计算来得到下一个状态的价值。同理,在 \(\alpha\) 的损失函数计算中,也不需要再对动作进行采样。
class SAC:
''' 处理离散动作的SAC算法 '''
def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr,
alpha_lr, target_entropy, tau, gamma, device):
# 策略网络
self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)
# 第一个Q网络
self.critic_1 = QValueNet(state_dim, hidden_dim, action_dim).to(device)
# 第二个Q网络
self.critic_2 = QValueNet(state_dim, hidden_dim, action_dim).to(device)
self.target_critic_1 = QValueNet(state_dim, hidden_dim,
action_dim).to(device) # 第一个目标Q网络
self.target_critic_2 = QValueNet(state_dim, hidden_dim,
action_dim).to(device) # 第二个目标Q网络
# 令目标Q网络的初始参数和Q网络一样
self.target_critic_1.load_state_dict(self.critic_1.state_dict())
self.target_critic_2.load_state_dict(self.critic_2.state_dict())
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),
lr=actor_lr)
self.critic_1_optimizer = torch.optim.Adam(self.critic_1.parameters(),
lr=critic_lr)
self.critic_2_optimizer = torch.optim.Adam(self.critic_2.parameters(),
lr=critic_lr)
# 使用alpha的log值,可以使训练结果比较稳定
self.log_alpha = torch.tensor(np.log(0.01), dtype=torch.float)
self.log_alpha.requires_grad = True # 可以对alpha求梯度
self.log_alpha_optimizer = torch.optim.Adam([self.log_alpha],
lr=alpha_lr)
self.target_entropy = target_entropy # 目标熵的大小
self.gamma = gamma
self.tau = tau
self.device = device
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
probs = self.actor(state)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
return action.item()
# 计算目标Q值,直接用策略网络的输出概率进行期望计算
def calc_target(self, rewards, next_states, dones):
next_probs = self.actor(next_states)
next_log_probs = torch.log(next_probs + 1e-8)
entropy = -torch.sum(next_probs * next_log_probs, dim=1, keepdim=True)
q1_value = self.target_critic_1(next_states)
q2_value = self.target_critic_2(next_states)
min_qvalue = torch.sum(next_probs * torch.min(q1_value, q2_value),
dim=1,
keepdim=True)
next_value = min_qvalue + self.log_alpha.exp() * entropy
td_target = rewards + self.gamma * next_value * (1 - dones)
return td_target
def soft_update(self, net, target_net):
for param_target, param in zip(target_net.parameters(),
net.parameters()):
param_target.data.copy_(param_target.data * (1.0 - self.tau) +
param.data * self.tau)
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device) # 动作不再是float类型
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
# 更新两个Q网络
td_target = self.calc_target(rewards, next_states, dones)
critic_1_q_values = self.critic_1(states).gather(1, actions)
critic_1_loss = torch.mean(
F.mse_loss(critic_1_q_values, td_target.detach()))
critic_2_q_values = self.critic_2(states).gather(1, actions)
critic_2_loss = torch.mean(
F.mse_loss(critic_2_q_values, td_target.detach()))
self.critic_1_optimizer.zero_grad()
critic_1_loss.backward()
self.critic_1_optimizer.step()
self.critic_2_optimizer.zero_grad()
critic_2_loss.backward()
self.critic_2_optimizer.step()
# 更新策略网络
probs = self.actor(states)
log_probs = torch.log(probs + 1e-8)
# 直接根据概率计算熵
entropy = -torch.sum(probs * log_probs, dim=1, keepdim=True) #
q1_value = self.critic_1(states)
q2_value = self.critic_2(states)
min_qvalue = torch.sum(probs * torch.min(q1_value, q2_value),
dim=1,
keepdim=True) # 直接根据概率计算期望
actor_loss = torch.mean(-self.log_alpha.exp() * entropy - min_qvalue)
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# 更新alpha值
alpha_loss = torch.mean(
(entropy - target_entropy).detach() * self.log_alpha.exp())
self.log_alpha_optimizer.zero_grad()
alpha_loss.backward()
self.log_alpha_optimizer.step()
self.soft_update(self.critic_1, self.target_critic_1)
self.soft_update(self.critic_2, self.target_critic_2)actor_lr = 1e-3
critic_lr = 1e-2
alpha_lr = 1e-2
num_episodes = 200
hidden_dim = 128
gamma = 0.98
tau = 0.005 # 软更新参数
buffer_size = 10000
minimal_size = 500
batch_size = 64
target_entropy = -1
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
env_name = 'CartPole-v0'
env = gym.make(env_name)
random.seed(0)
np.random.seed(0)
env.seed(0)
torch.manual_seed(0)
replay_buffer = rl_utils.ReplayBuffer(buffer_size)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = SAC(state_dim, hidden_dim, action_dim, actor_lr, critic_lr, alpha_lr,
target_entropy, tau, gamma, device)
return_list = rl_utils.train_off_policy_agent(env, agent, num_episodes,
replay_buffer, minimal_size,
batch_size)
/home/aikedaer/.local/lib/python3.9/site-packages/gym/envs/registration.py:593: UserWarning: [33mWARN: The environment CartPole-v0 is out of date. You should consider upgrading to version `v1`.[0m
logger.warn(
Iteration 0: 100%|██████████| 20/20 [00:00<00:00, 39.21it/s, episode=20, return=20.700]
Iteration 1: 100%|██████████| 20/20 [00:03<00:00, 5.08it/s, episode=40, return=12.000]
Iteration 2: 100%|██████████| 20/20 [00:03<00:00, 5.41it/s, episode=60, return=9.500]
Iteration 3: 100%|██████████| 20/20 [00:03<00:00, 5.29it/s, episode=80, return=9.900]
Iteration 4: 100%|██████████| 20/20 [00:03<00:00, 5.18it/s, episode=100, return=9.400]
Iteration 5: 100%|██████████| 20/20 [00:03<00:00, 5.39it/s, episode=120, return=9.300]
Iteration 6: 100%|██████████| 20/20 [00:13<00:00, 1.43it/s, episode=140, return=64.000]
Iteration 7: 100%|██████████| 20/20 [00:56<00:00, 2.83s/it, episode=160, return=158.500]
Iteration 8: 100%|██████████| 20/20 [00:58<00:00, 2.92s/it, episode=180, return=147.700]
Iteration 9: 100%|██████████| 20/20 [01:07<00:00, 3.39s/it, episode=200, return=188.200]
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('SAC on {}'.format(env_name))
plt.show()
mv_return = rl_utils.moving_average(return_list, 9)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('SAC on {}'.format(env_name))
plt.show()


可以发现,SAC 在离散动作环境车杆下具有完美的收敛性能,并且其策略回报的曲线十分稳定,这体现出 SAC 可以在离散动作环境下平衡探索与利用的优秀性质。
14.6 小结
本章首先讲解了什么是最大熵强化学习,并通过控制策略所采取动作的熵来调整探索与利用的平衡,可以帮助读者加深对探索与利用的关系的理解;然后讲解了 SAC 算法,剖析了它背后的原理以及具体的流程,最后在连续的倒立摆环境以及离散的车杆环境中进行了 SAC 算法的代码实践。 由于有扎实的理论基础和优秀的实验性能,SAC 算法已经成为炙手可热的深度强化学习算法,很多新的研究基于 SAC 算法,第 17 章将要介绍的基于模型的强化学习算法 MBPO 和第 18 章将要介绍的离线强化学习算法 CQL 就是以 SAC 作为基本模块构建的。
14.7 参考文献
[1] HAARNOJA T, ZHOU A, ABBEEL P,et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor [C] // International conference on machine learning, PMLR, 2018:1861-1870.
[2] HAARNOJA T, ZHOU A, HARTIKAINEN K, et al. Soft actor-critic algorithms and applications [J]. 2018.
[3] HAARNOJA T, TANG H, ABBEEL P,et al. Reinforcement learning with deep energy-based policies [C] // International conference on machine learning, PMLR, 2017:1352-1361.
[4] SCHULMAN J, CHEN X, ABBEEL P. Equivalence between policy gradients and soft q-learning [J]. 2017.
打赏作者
